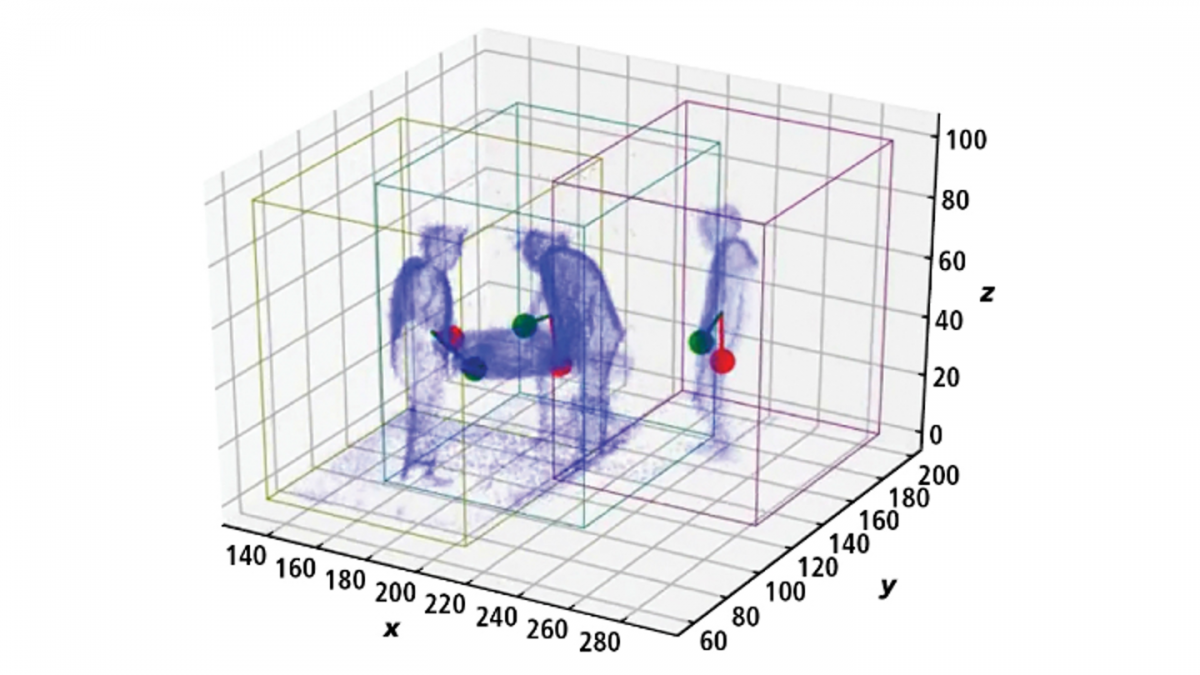
Microsoft opracował układ śledzący 4D oparty na równoczesnym użyciu wielu kamer ToF (Time of Flight) 3D, pomiarze wielkości i oznaczeniach czasu. System może rozpoznać zachowanie i śledzić 12 osób jednocześnie, a istnieje możliwość zwiększenia tej liczby.
Przemysł inżynierski i konstrukcyjny często opiera się na modelowaniu 4D. Model 4D proponowanego budynku, projekt przestrzeni wokół mogą pokazać odbiorcy, jak budynek powinien wyglądać podczas poszczególnych etapów pracy projektu. Jeśli projekt budynku ulegnie zmianom,, które naruszają prace poszczególnych etapów, model 4D zmienia się również odpowiednio.
W tradycyjnym obrazowaniu 3D, takim jak LiDAR, chmura punktów reprezentuje kontury obiektów. Te systemy nie mierzą odległości pomiędzy danymi obrysami, natomiast nowy system Microsoftu wykorzystuje kamery Azure Kinect ToF, by zmierzyć przestrzeń lub przekonwertować ją w woksele zamiast w piksele.
Układ śledzący rejestruje dane wokseli z prędkością 30 ramek na sekundę. Każdy woksel w każdej klatce ma przypisane współrzędne x, y, z oraz czwartą wartość T – czas, która oznacza moment zarejestrowania go. Zarejestrowane woksele są przekształcane w dane wolumetryczne lub ilość zajmowanej przestrzeni w ramce, z której układ śledzący 4D może stworzyć mapę przestrzeni 3D.
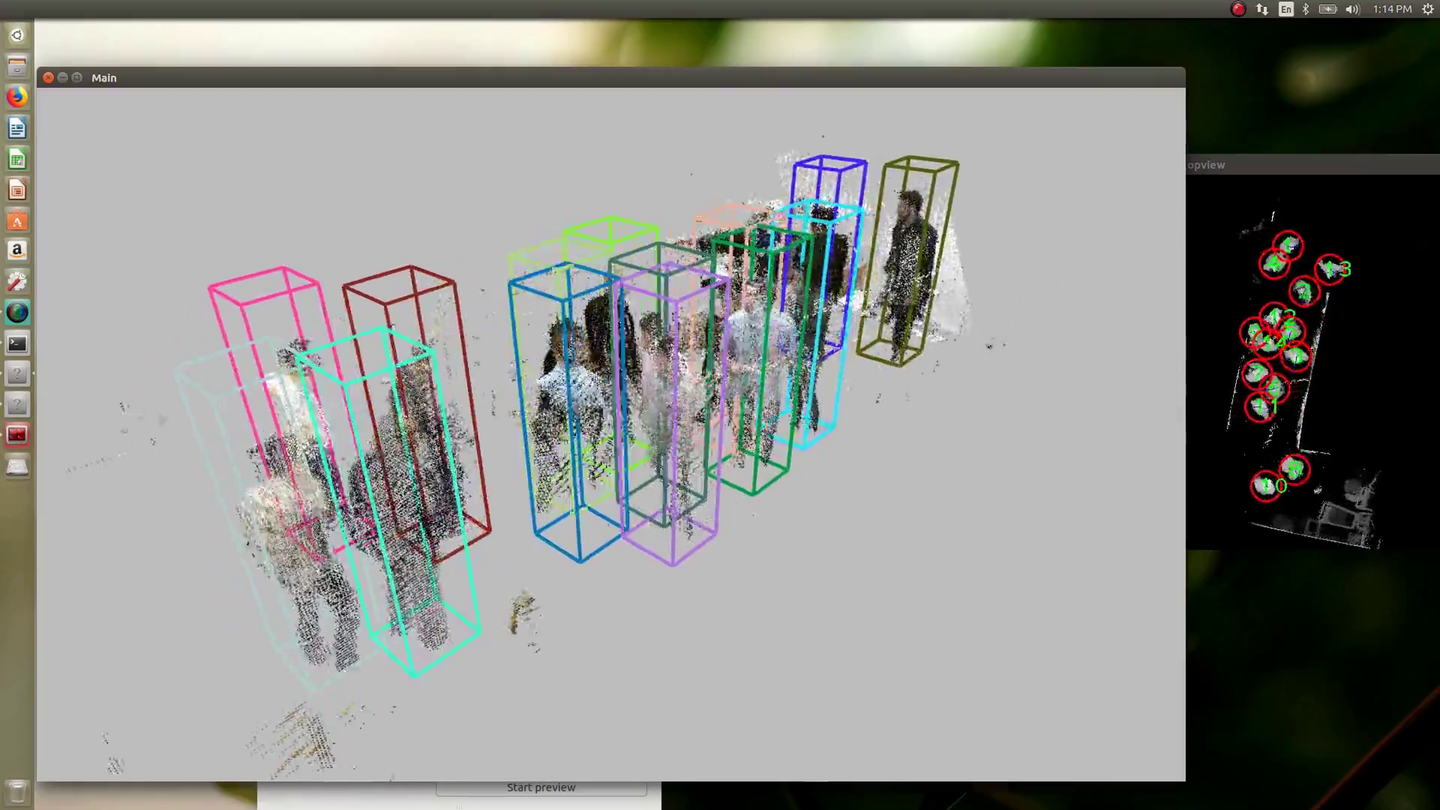
Algorytmy systemu śledzącego następnie zamieniają cały obszar mapy w częściowe objętości lub masy zarejestrowanych wokseli. Algorytm detekcji opierający się o neuronową sieć splatającą skanuje częściowe objętości w celu poszukiwania wzorów, które mogą reprezentować osoby.
Algorytmy detekcji określają prawdopodobieństwo czy dana grupa pikseli to twarz lub znak drogowy na podstawie danych treningowych. Układ śledzący 4D Microsoftu określa prawdopodobieństwo tego, czy dane woksele to człowiek na podstawie ruchu części objętości w czasie.
„Normalnie człowiek nie porusza się od jednego punktu i nie skacze nagle 10 metrów dalej.” – mówi dr Hao Jiang, jeden z wynalazców układu śledzącego 4D. –„Jeśli weźmiemy pod uwagę punktu z otoczenia, bliskie sąsiedztwo zarejestrowanej mapy, możemy podążać za częściową objętością i określić, czy jest to faktycznie człowiek czy nie. Sam algorytm może osiągnąć 98% skuteczności, a z procedurą śledzenia system jest w stanie dojść do prawie 100% dokładności.
Gdy układ śledzący 4D rozpozna z sukcesem człowieka w konkretnej części mapy, system może obserwować jego ruchy i rozpoznawać je przez zmianę obserwacji poszczególnych części w czasie.
„System używa wielu kluczy.” – tłumaczy Jiang. – „ Jednym elementem jest kształt. Jeśli spojrzymy na wygenerowaną chmurę punktów, widać, że osoba siedzi, ponieważ jej noga jest zgięta. Jej kształt jest inny niż wtedy, gdy stoi. Używamy także informacji chwilowych. Gdy ktoś siada, widać określoną strukturę ruchu. Kształt zmienia się z pozycji osoby stojącej do siedzącej, co też daje wskazówkę, że osoba już siedzi.”
Układ śledzący uczy się rozpoznawać indywidualne czynności z nagrań z sesji, podczas których pojedyncze osoby wykonywały konkretne akcje takie jak np. siadanie. Uchwycone dane są nazywane siadaniem. Takie nagrania tej czynności wykonywanych przez wiele osób posłużyły do wyszkolenia algorytmu do rozpoznawania tej czynności.
„Niewiele osób pracuje nad tym rodzajem rozpoznawania czynności.” – kontynuuje Jiang. – „ Nie rejestrujemy danych i później nie pracujemy nad ich rozpoznaniem. System śledzi i rozpoznaje w czasie rzeczywistym. Wynik możemy zobaczyć od razu na ekranie. Jest to coś znacznie różniącego się od tradycyjnych metod.”
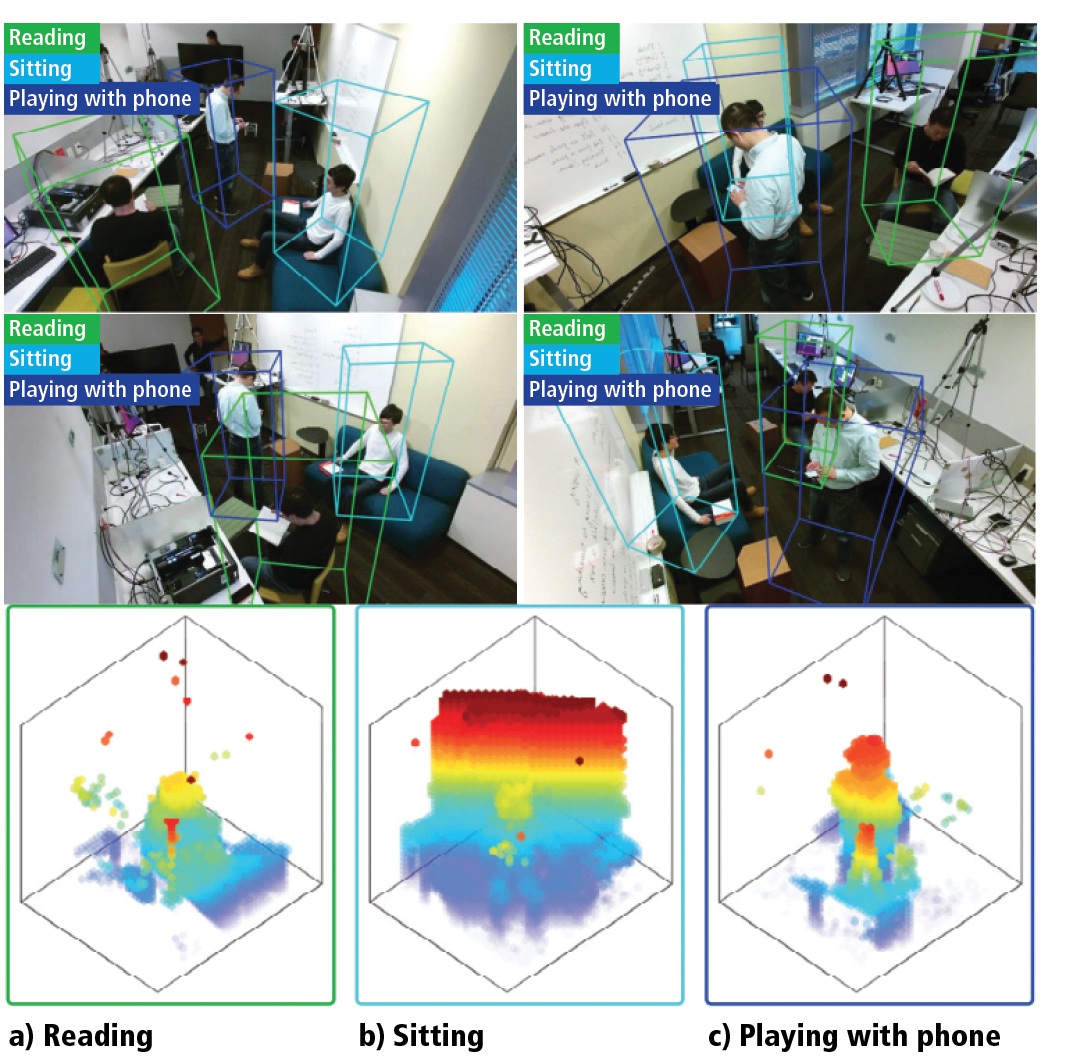
We wczesnych testach system mógł rozpoznawać szesnaście czynności między innymi czytanie książki, siedzenie, wskazywanie, otwieranie szuflady, jedzenie, odchylanie, kopanie. Niektóre z tych czynności znacznie się różniły od innych. Czynności takie jak picie lub trzymanie telefonu mogą jednak wyglądać całkiem podobnie.
Microsoft wynalazł dodatkowy moduł uwagi, który włącza powtarzalne sieci neuronowe (RNN – ang. Recurrent Neural Networks) w celu zróżnicowania podobnych czynności. Ten moduł działa jak automatyczny generator obszaru zainteresowań (ROI).
„ Jeśli ktoś pije coś, chcemy patrzeć w rejon głowy.” – mówi Jiang. – „ Nie potrzebujemy obrazu całej postaci. Ruch nóg ma mały związek z piciem i nie jest nam w danej chwili potrzebny.”
„Moduł uwagi określa prawdopodobieństwo, że dany obszar jest jednoznaczny z daną czynnością. System dodaje wtedy wagi do wskaźników w tym regionie i zapamiętuje wynik generując nową cechę przy dalszym rozpoznawaniu czynności.” – dodaje Jiang.
Dodatkowy moduł uwagi nie posiada jednak wytycznych, gdzie ma szukać. Moduł trenuje się sam przez powtarzanie akcji rozpoznawania, która część danych jest najbardziej istotna dla rozpoznawanej czynności. Na przykład jeśli ktoś czyta książkę, moduł zwraca większą uwagę na ręce i dłonie, by pomóc potwierdzić wykonywanie danej czynności. Jeśli ktoś wygląda na osobę, która jest zajęta kopaniem, moduł zaczyna zwracać większą uwagę na rejon nóg i stóp.
„Sieci neuronowe przeglądają te przykłady i określają, gdzie powinna być kierowana uwaga, aby osiągnąć lepsze wyniki.” – informuje Jiang. – „ Wagi tych elementów są dynamiczne, niezdefiniowane wcześniej. Moduł widzi, że ktoś jest prawdopodobnie w trakcie jakiejś czynności i decyduje się zwrócić uwagę do istotnych części regionu, aby potwierdzić tę czynność.”
Microsoft testował dokładność swojego systemu w porównaniu z pięcioma innymi: ShapeContext, Moment, Skeleteon, Color plus Depth i PointNet. Każdy z nich bazował na tych samym danych treningowych. Testy były przeprowadzane w różnych scenach z różnymi ludźmi o różnych kształtach ciała, płci, wzroście i obiektach takich jak krzesła, stoły, pudła, szuflady, kubki i książki.
Ludzie biorący udział w testach byli podzieleni w pięć grup i wykonywali szesnaście różnych czynności, na których był szkolony system. Każdej osobie w każdej ramce została przypisana jakaś czynność do wykonania. Test był zdany pozytywnie, jeśli system dobrze określił wykonywaną czynność. Obraz rejestrowały cztery kamery RGBD. Wyniki testów były następujące: ShapeContext 40.38%, Moments 44.9%, Skeleton 54.94%, Color plus Depth 59.96%, PointNet 57.78%. Układ śledzący 4D Microsoft osiągnął dokładność rozpoznawania na poziomie 88.98%.
W największym teście systemu badacze opróżnili podłogę biura Microsoft w Bellevue w USA, która ma kilka tysięcy stóp kwadratowych, ustawili 26 kamer Azure Kinect, wnieśli trochę mebli w celu zasymulowania otoczenia biurowego i wprowadzili do pomieszczenia 50 osób jako obiekty testu.
Moc i przepustowość więzów, nie liczba osób, stanowi ograniczenie potencjalnej wielkość systemu śledzenia. Dokładność rozpoznawania czynności nie ma związku z liczbą osób, które śledzi układ indywidualnie i używa osobnych elementów do rozpoznania ich czynności.
„Zagęszczenie ludzi ma wpływ na dokładność.” – mówi Jiang. – „ Tłum tak naprawdę stanowi mocną stronę proponowanego rozwiązania. Liczba osób wpływa na czas całościowego zastosowania metody. Jeśli w jakimś zastosowaniu szybkość przesyłu ramek na sekundę będzie zbyt mała, można dodać więcej procesorów GPU, ponieważ metoda pozwala na wykonywanie operacji na wielu kartach i urządzeniach.”
Układ śledzący 4D Microsoftu nie rozpoznaje jeszcze dokładnie obiektów. Niska częstotliwość chmury punktów stanowi największe wyzwanie. Obserwacja kontekstualna może stanowić rozwiązanie.
„Umiemy rozpoznać obiekt wynikający z kontekstu sytuacji, na przykład w trakcie zakupów.” – opowiada Jiang. – „ Klienci biorą produkty z półki, a my uczymy algorytm rozpoznawania produktu, pudełka. Mamy dosyć dokładny lokalizator dłoni. Jeśli wiemy, gdzie jest punkt dłoni, możemy rozpoznać obiekt w dłoni.”
Innym przykładem jest czytanie książki, które zależy od sposobu trzymania książki w rękach. Jeśli system będzie w stanie prawidłowo rozpoznać czynność, będzie też prawdopodobnie w stanie nauczyć się rozpoznawania książki, ponieważ jeśli ktoś zostanie zidentyfikowany jako czytający, to będzie prawdopodobnie czytał książkę trzymaną w dłoniach. Ta technika znajduje zastosowanie dla większych obiektów. Dla rzeczy mniejszych na przykład szminki do rozpoznania obiektu może być potrzebne dodatkowe źródło danych RGB.
„Możemy stosować chmurę punktów do lokalizowania dłoni w dosyć łatwy sposób, a wtedy możemy wyświetlić kolor obrazu.” – dodaje Jiang. – „ To prawdopodobnie dobra droga do dodania szczegółowego rozpoznawania obiektów w naszym nowym systemie.”
Źródło: www.vision-systems.com